在這個章節我們將學習 Clustering(分群) and Similarity(相似度)
通常我們可以從資料當中推理出某種潛在的結構(我想這裡指的結構,可以把他想成我們一般文章中的體裁記敘文、抒情文、論說文、應用文,甚至可以進一步想成,文章的性質(體育、文學、財經、生活...))
同樣的我們將透過例子來引出實際的內容
假設你正在讀一篇你感興趣關於足球的文章
如果這篇文章來自阿根廷你會看到關鍵字"football"如果來自巴西則會看到"futebol"
接下來我想要找出另一篇你同樣感興趣的文章
但是我不能夠期望,你讀完全世界文章後來一一告訴我那些是你感興趣的
所以我希望能夠自動檢索出你感興趣的文章,這時候問題就來了...
我們該如何衡量文章之間的相似度?
顯然的我需要一種方法來判斷其他文章跟你正在看的文章的相似度
另一個問題是,我該如何從全部的文章中檢索出下一篇推薦給你的文章?
首先要考慮的是,我們該如何處理我的資料?
最流行的方法之一稱為Bag-of-words model
這個模型忽略了句子的文章當中句子排列的順序,將它們全部丟到一個袋子裡面打散
其結果與原始文章在袋子裡對應是完全一樣的
忽略句子的結構與順序,僅僅只考慮丹自在文件中出現的次數
舉個例子,假設這文件中只有兩句話
"Carlos calls the sport futbol, Emily calls the sport soccer."
為了計算每個單字在文件出現的次數,我們定義一個考慮我們語言的向量如下圖所示
單字表中與文件出現相同的單字時,向量+1
最後將構成一個用來表示單字在文件中出現的次數有幾次的 Sparse matrix

接著假設你正在閱讀一篇文章,我該如何找出其他你感興趣的文章呢?以下面的例子來說
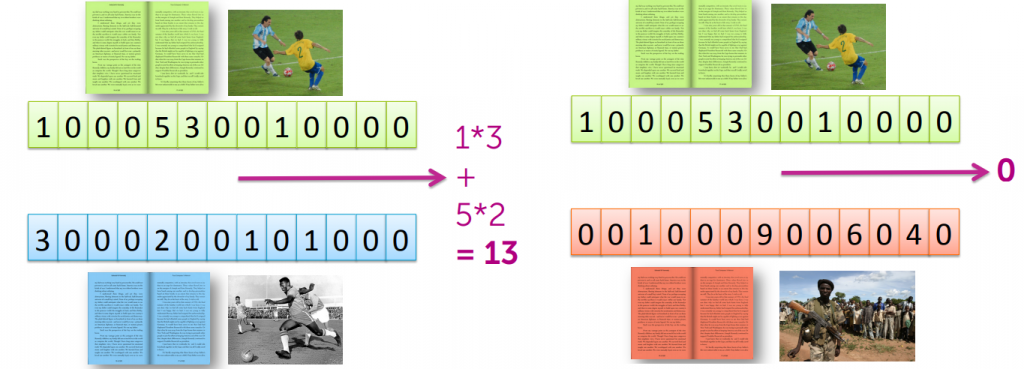
假設有兩篇文章,我們將其透過Bag-of-words model,並且透過單字出現的次數建立 Sparse matrix
接著我們可以將兩篇文章對應的向量元素求出其點積並相加,數字將會呈現兩篇文章的相似度
但這種用單字統計度量文章相似度的方法有一個很大的問題
現在我們把同一份文章,複製並且黏合成為兩倍長度時,我們將得到更高的相似度
這在文章檢索時並不合理,因為這將有助於更長的文章
那該如何解決這個問題呢?一般來說我們傾向於 normalize 這個向量
我們求出這個單字統計向量的範數(平方合和再取平方根)
透過這層處理,即便長度不一,我依然可以將他們置於相同的地位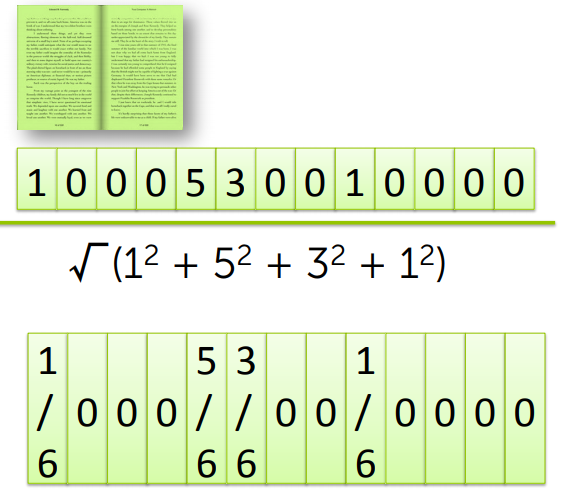



 iThome鐵人賽
iThome鐵人賽